Jak wyodrębnić tabele z dokumentów PDF
W tym artykule dowiesz się, jak wyodrębnić tabele z dokumentów PDF(extract tables from PDF documents) . Możesz mieć wiele plików PDF zawierających wiele tabel, których chcesz używać osobno. Kopiowanie(Copying) i wklejanie tych tabel nie jest dobrą opcją, ponieważ może nie dać oczekiwanych wyników, dlatego potrzebujesz innych prostych opcji, które mogą wyodrębnić tabele z pliku PDF i zapisać je jako osobne pliki.
Większość z tych narzędzi do wyodrębniania tabel PDF(PDF table extractor tools) nie może pomóc, jeśli tabela PDF jest skanowana. W takim przypadku należy najpierw umożliwić przeszukiwanie pliku PDF(make the PDF searchable) , a następnie wypróbować te opcje.
Wyodrębnij tabele z dokumentów PDF
W tym poście dodaliśmy 2 bezpłatne usługi online i 3 bezpłatne oprogramowanie do wyodrębniania tabel z pliku PDF :
- PDF do XLS
- PDFtoExcel.com
- Płytka
- Narzędzie wielofunkcyjne ByteScout PDF
- Sejda PDF Pulpit.
1] PDF do XLS
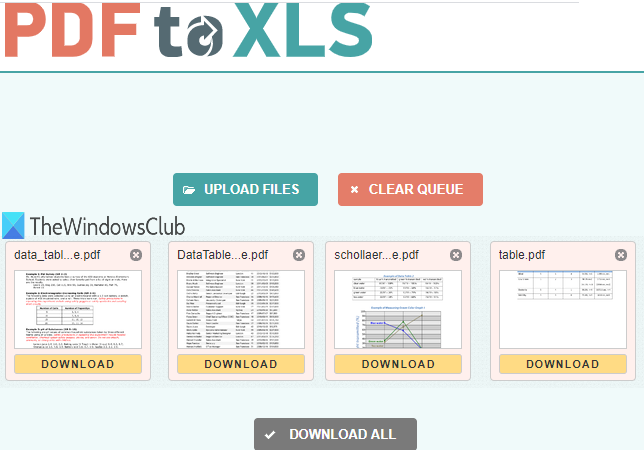
PDF do XLS to jedna z najlepszych opcji wyodrębniania tabel z PDF . Posiada dwie cechy, które sprawiają, że jest poręczny. Możesz pobrać tabele z 20 dokumentów PDF(20 PDF) razem. Ponadto wyodrębnianie tabeli PDF jest automatyczne. (PDF)Generuje dane wyjściowe jako plik XLSX . Jeśli plik PDF zawiera wiele tabel, każda tabela jest przechowywana osobno w różnych arkuszach wyjściowego pliku XLSX .
Otwórz stronę główną(Open the homepage) tej usługi. Następnie przeciągnij i upuść pliki PDF lub użyj przycisku PRZEŚLIJ PLIKI(UPLOAD FILES) . Każdy przesłany plik PDF(PDF) jest automatycznie konwertowany do pliku w formacie XLSX. Gdy pliki wyjściowe będą gotowe, możesz je pobrać jeden po drugim lub pobrać plik ZIP , który będzie zawierał wszystkie pliki wyjściowe.
2] PDFtoExcel.com

Usługa PDFtoExcel.com(PDFtoExcel.com) może wyodrębniać tabele z jednego pliku PDF(PDF) jednocześnie, ale obsługuje wiele platform do przesyłania plików PDF . Obsługuje platformy OneDrive , Desktop , Google Drive i Dropbox do przesyłania plików (Dropbox)PDF . Również proces konwersji jest automatyczny.
Strona główna tej usługi jest tutaj(here) . Tam wybierz opcję przesyłania, aby dodać plik PDF(PDF) . Następnie automatycznie przesyła i konwertuje plik PDF(PDF) do pliku Excel ( XLSX ). Gdy dane wyjściowe będą gotowe, otrzymasz link do pobrania, aby zapisać plik wyjściowy zawierający tabele PDF .
Uwaga:(Note: ) chociaż ta usługa wspomina, że może również wyodrębniać tabele z zeskanowanych plików PDF , nie działała dla mnie. Nadal możesz go wypróbować dla zeskanowanego pliku PDF(PDF) .
3] Tabula

Tabula to potężne oprogramowanie, które może automatycznie wykrywać tabele obecne w pliku PDF(PDF) , a następnie umożliwia zapisywanie tych tabel jako pliku TSV , JSON lub CSV . Możesz wybrać opcję zapisywania oddzielnych plików CSV dla każdej tabeli (CSV)PDF lub zapisywania wszystkich tabel w jednym pliku CSV .
Aby pobrać ten ekstraktor tabel PDF z otwartym kodem źródłowym , (open-source)kliknij tutaj(click here) . Wymaga również Javy(requires Java) do poprawnego działania i używania.
Wyodrębnij pobrany plik ZIP i uruchom plik tabula.exe . Otworzy stronę w domyślnej przeglądarce. Jeśli strona nie jest otwarta, dodaj http://localhost:8080 w przeglądarce i naciśnij Enter .
Teraz zobaczysz jego interfejs, w którym możesz użyć opcji Przeglądaj(Browse) , aby dodać plik PDF . Następnie naciśnij przycisk Importuj(Import) . Po dodaniu pliku PDF(PDF) możesz zobaczyć strony PDF w jego interfejsie.
Użyj przycisku Autodetect Tables , a automatycznie podświetli wszystkie tabele obecne w tym pliku PDF(PDF) . Możesz także ręcznie podświetlić tabelę, wybierając konkretną tabelę. Jeśli chcesz, możesz również usunąć wybrane przez siebie stoły(remove selected tables) .
Pomoże Ci to zapisać tylko te tabele, które chcesz. Gdy podświetlone są tabele PDF , kliknij przycisk Podgląd i eksport wyodrębnionych danych(Preview & Export Extracted Data) .
Na koniec użyj menu rozwijanego dostępnego w górnej części, aby wybrać format wyjściowy i naciśnij przycisk Eksportuj(Export) . Spowoduje to zapisanie tabel PDF w wybranym przez Ciebie pliku formatu wyjściowego.
4] Narzędzie wielofunkcyjne ByteScout PDF
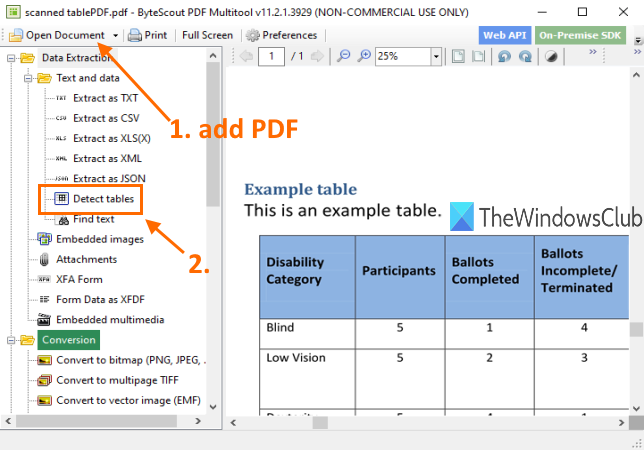
Jak sama nazwa wskazuje, to oprogramowanie zawiera wiele narzędzi. Posiada narzędzia takie jak konwertowanie plików PDF na wielostronicowy TIFF(convert PDF to multipage TIFF) , obracanie dokumentów PDF(rotate PDF document) , uniemożliwianie wyszukiwania plików PDF(make PDF unsearchable) , optymalizacja plików PDF(optimize PDF) , dodawanie obrazów do plików PDF(add an image to PDF) i wiele innych. Dostępna jest również funkcja wykrywania tabel PDF(PDF) , co jest całkiem niesamowite. Zaletą tego narzędzia jest możliwość wyodrębniania tabel(extract tables from scanned PDF) również ze zeskanowanego pliku PDF. Możesz wykryć tabele na wielu stronach, a następnie wyodrębnić je jako plik w formacie CSV , XLS , XML , TXT lub JSON . Przed wyodrębnieniem pozwala również ustawić zakres stron(page range)aby wyodrębnić tabele tylko z określonych stron.
Możesz pobrać to oprogramowanie tutaj(here) . Jest bezpłatny wyłącznie do użytku niekomercyjnego(free for non-commercial use) . Po instalacji uruchom to oprogramowanie i użyj opcji Otwórz dokument(Open Document) , aby dodać plik PDF . Następnie kliknij narzędzie Wykryj tabele(Detect tables) , jak pokazano na powyższym obrazku. To narzędzie znajduje się w kategorii Wyodrębnianie danych(Data Extraction) .
Otworzy się okno, w którym możesz ustawić warunki wykrywania tabel. Możesz na przykład ustawić minimalną liczbę kolumn, wierszy, minimalne podziały wierszy między tabelami, ustawić tryb wykrywania tabeli na tabelę z obramowaniem lub bez obramowania itp. Użyj opcji lub zachowaj ustawienia domyślne.
Następnie naciśnij przycisk Wykryj następny stół(Detect next table) w tym polu. Zidentyfikuje i wybierze tabelę na bieżącej stronie. W ten sposób możesz przejść na inną stronę i wykryć więcej tabel.
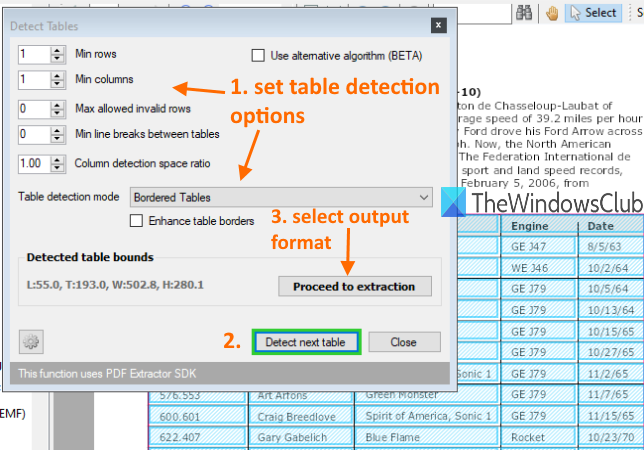
Po zakończeniu użyj przycisku Przejdź do wyodrębniania(Proceed to extraction) i wybierz format wyjściowy. Na koniec możesz użyć opcji, aby zapisać tabele z bieżącej strony lub zdefiniować zakres stron i zapisać wynik.
Narzędzie daje zadowalający wynik. Czasami jednak może wykryć inną zawartość w PDF i może nie być w stanie wyodrębnić tabel z wielu stron. W takim przypadku powinieneś używać go do pobierania i zapisywania tabel jedna po drugiej.
5] Sejda na pulpit PDF
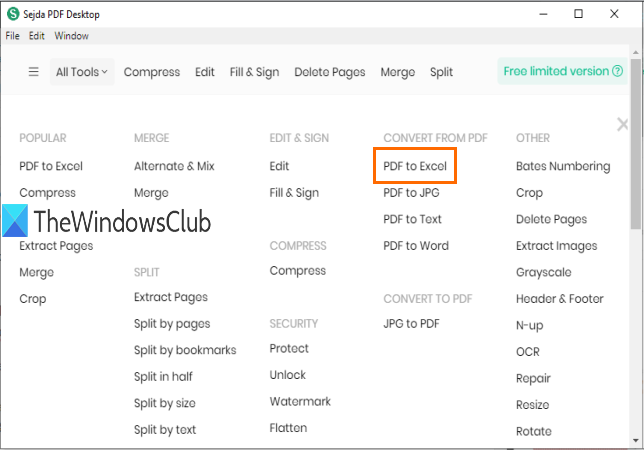
Sejda PDF Desktop to także oprogramowanie wielofunkcyjne. Może optymalizować lub kompresować PDF(compress PDF) , dodawać znak wodny do PDF, usuwać ograniczenia z PDF(remove restrictions from PDF) , edytować dokument PDF itp. Jednak jego bezpłatny plan ma ograniczenia. W bezpłatnym abonamencie można wykonać tylko 3 zadania dziennie. Ponadto limit rozmiaru PDF to (PDF)50 MB lub 10 stron(10 pages) .
Możesz użyć narzędzia do konwersji plików PDF na Excel(PDF to Excel) , aby wyodrębnić tabele PDF . Automatycznie wykrywa tabele na stronach PDF i pozwala zapisać te tabele jako XLSX lub CSV .
Link do jego pobrania znajduje się tutaj(here) . Po instalacji użyj narzędzia PDF do Excela(Excel) z jego głównego interfejsu. Po wybraniu tego narzędzia użyj przycisku Wybierz pliki PDF(Choose PDF files) . Do darmowego planu można dodać tylko jeden plik PDF .(PDF)
Po dodaniu pliku PDF(PDF) pojawią się przyciski Konwertuj PDF na CSV(Convert PDF to CSV) i Konwertuj PDF na Excel(Convert PDF to Excel) . Użyj przycisku, a następnie możesz zapisać dane wyjściowe w wybranej lokalizacji na komputerze.
Jego narzędzie do wykrywania tabel PDF jest dobre. (PDF)Nie musisz ręcznie wykrywać tabel. Czasami jednak może zawierać inną treść tekstową jako tabelę PDF i przechowywać ją w danych wyjściowych. Ale ogólne wyniki są dobre.
To wszystko.
Oto kilka dobrych narzędzi do wyodrębniania tabel z plików PDF(PDF) . Oprogramowanie Tabula(Tabula) jest bardziej efektywne niż inne narzędzia. Mimo to możesz wypróbować wszystkie narzędzia i sprawdzić, które pomagają.
Podobne brzmi:(Similar reads:)
- Wyodrębnij załączniki z PDF(Extract attachments from PDF)
- Wyodrębnij zaznaczony tekst z pliku PDF(Extract highlighted text from PDF) .

About the author
Jestem inżynierem Windows, ios, pdf, błędów, gadżetów z ponad 10-letnim doświadczeniem. Pracowałem nad wieloma wysokiej jakości aplikacjami i frameworkami Windows, takimi jak OneDrive dla Firm, Office 365 i nie tylko. Moja ostatnia praca obejmowała opracowanie czytnika PDF dla platformy Windows i pracę nad tym, aby komunikaty o błędach były bardziej zrozumiałe dla użytkowników. Dodatkowo od kilku lat jestem zaangażowany w rozwój platformy ios i dobrze znam zarówno jej funkcje, jak i dziwactwa.
Related posts
Konwerter dokumentów: Konwertuj pliki DOC, PDF, DOCX, RTF, TXT, HTML
Co to jest plik PPS? Jak przekonwertować PPS na PDF w Windows 11/10?
Tekst PDF znika podczas edycji lub zapisywania pliku w systemie Windows 11/10
Najlepsze bezpłatne narzędzia online do edytowania plików PDF, które są oparte na chmurze
Darmowe narzędzie online PDF Editor do edycji plików PDF - PDF Tak
Kompresuj oprogramowanie PDF: Kompresuj pliki PDF za pomocą narzędzi online PDF Reducer
Jak wyróżnić tekst w dokumentach PDF w przeglądarce Microsoft Edge
Adobe Reader nie działa w systemie Windows 11/10
Jak przekonwertować zeskanowany plik PDF na plik PDF z możliwością przeszukiwania?
PDF Candy to kompleksowe narzędzie online do zarządzania plikami PDF
Jak przycinać strony PDF w systemie Windows 11 za pomocą narzędzia online lub bezpłatnego oprogramowania?
Jak przekonwertować plik Excel do PDF online za pomocą Dysku Google
Jak konwertować dokumenty do formatu PDF za pomocą CutePDF dla Windows 10?
Włącz tryb widoku dwóch stron dla plików PDF w przeglądarce PDF Google Chrome
Jak wyodrębnić i zapisać metadane PDF w systemie Windows 11/10?
Jak włączyć układ dwustronicowy dla plików PDF w przeglądarce Edge
Konwertuj dokumenty Word, PowerPoint, Excel do formatu PDF za pomocą Dokumentów Google
Najlepsze darmowe oprogramowanie PDF Stamp Creator dla systemu Windows 10
Usuń ograniczenia PDF za pomocą bezpłatnego oprogramowania lub narzędzi online
Konwerter witryn 7-PDF: Konwertuj strony internetowe do formatu PDF