Czym są uczenie maszynowe i uczenie głębokie w sztucznej inteligencji
Urządzenia podłączone do Internetu(Internet) nazywane są urządzeniami inteligentnymi. Prawie wszystko, co związane z Internetem(Internet) , jest znane jako inteligentne urządzenie(smart device) . W tym kontekście można powiedzieć, że kod, który sprawia, że urządzenia są INTELIGENTNIEJSZE –(SMARTER – ) tak aby mogły działać przy minimalnej lub bez ingerencji człowieka – jest oparty na sztucznej inteligencji(Artificial Intelligence) (AI). Pozostałe dwa, a mianowicie: uczenie maszynowe(Machine Learning) (ML) i uczenie głębokie(Deep Learning) (DL), to różne typy algorytmów zbudowanych w celu zwiększenia możliwości inteligentnych urządzeń. Zobaczmy poniżej AI vs ML vs DL , aby zrozumieć, co robią i jak są połączone z AI.
Czym jest sztuczna inteligencja w odniesieniu do ML i DL?
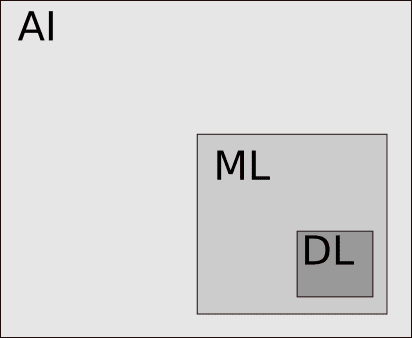
AI można nazwać nadzbiorem procesów uczenia maszynowego(Machine Learning) (ML) i procesów głębokiego uczenia(Deep Learning) (DL). AI jest zwykle terminem zbiorczym używanym do ML i DL. Głębokie uczenie(Deep Learning) jest ponownie podzbiorem uczenia maszynowego(Machine Learning) (patrz obrazek powyżej).
Niektórzy twierdzą, że uczenie maszynowe(Machine Learning) nie jest już częścią uniwersalnej sztucznej inteligencji. Mówią, że ML jest kompletną nauką samą w sobie i dlatego nie musi być nazywana w odniesieniu do sztucznej inteligencji(Artificial Intelligence) . Sztuczna inteligencja rozkwita na danych: Big Data . Im więcej danych zużywa, tym jest dokładniejsze. Nie jest tak, że zawsze będzie dobrze przewidywał. Będą też fałszywe flagi. Sztuczna inteligencja szkoli się na tych błędach i staje się lepsza w tym, co ma robić – z nadzorem człowieka lub bez niego.
Sztuczna inteligencja nie może być właściwie zdefiniowana, ponieważ przeniknęła do prawie wszystkich branż i wpływa na zbyt wiele rodzajów (biznesowych) procesów i algorytmów. Można powiedzieć, że sztuczna inteligencja(Intelligence) opiera się na Data Science (DS: Big Data ) i zawiera uczenie maszynowe(Machine Learning) jako odrębną część. Podobnie (Likewise)głębokie uczenie(Deep Learning) jest odrębną częścią uczenia maszynowego(Machine Learning) .
W sytuacji, gdy rynek IT się przechyla, przyszłość będzie zdominowana przez inteligentne urządzenia połączone z internetem, zwane Internetem Rzeczy (IoT)(Internet of Things (IoT)) . Urządzenia inteligentne(Smart) to sztuczna inteligencja: bezpośrednio lub pośrednio. Wykorzystujesz już sztuczną inteligencję (AI) w wielu zadaniach w swoim codziennym życiu. Na przykład pisanie na klawiaturze smartfona, która jest coraz lepsza w „sugestii słów”. Wśród innych przykładów, w których nieświadomie masz do czynienia ze sztuczną inteligencją(Artificial Intelligence) , są wyszukiwanie rzeczy w Internecie(Internet) , zakupy online i oczywiście zawsze inteligentne skrzynki e-mail Gmaila(Gmail) i Outlooka .(Outlook)
Co to jest uczenie maszynowe
Uczenie(Learning) maszynowe to dziedzina sztucznej inteligencji(Artificial Intelligence) , której celem jest sprawienie, aby maszyna (lub komputer lub oprogramowanie) uczyła się i trenowała bez większego programowania. Takie urządzenia wymagają mniej programowania, ponieważ wykorzystują ludzkie metody do wykonywania zadań, w tym uczenia się, jak działać lepiej. Zasadniczo(Basically) ML oznacza trochę zaprogramowanie komputera/urządzenia/oprogramowania i umożliwienie mu samodzielnej nauki.
Istnieje kilka metod ułatwiających uczenie maszynowe(Machine Learning) . Spośród nich następujące trzy są szeroko stosowane:
- Nadzorowane,
- Bez nadzoru i
- Nauka wzmacniania.
Uczenie nadzorowane w uczeniu maszynowym(Machine Learning)
Nadzorowane w pewnym sensie, że programiści najpierw dostarczają maszynie oznakowane dane i już przetworzone odpowiedzi. W tym przypadku etykiety oznaczają nazwy wierszy lub kolumn w bazie danych lub arkuszu kalkulacyjnym. Po wprowadzeniu ogromnych zbiorów takich danych do komputera, jest on gotowy do analizy kolejnych zbiorów danych i samodzielnego dostarczenia wyników. Oznacza to, że nauczyłeś komputer, jak analizować dostarczane do niego dane.
Zwykle potwierdza się to za pomocą zasady 80/20. Ogromne(Huge) zestawy danych są przesyłane do komputera, który próbuje i uczy się logiki kryjącej się za odpowiedziami. 80 procent danych ze zdarzenia trafia do komputera wraz z odpowiedziami. Pozostałe 20 procent jest karmione bez odpowiedzi, aby sprawdzić, czy komputer może uzyskać prawidłowe wyniki. Te 20 procent służy do sprawdzania, w jaki sposób komputer (maszyna) się uczy.
Nienadzorowane uczenie maszynowe
Nienadzorowane uczenie ma miejsce, gdy maszyna jest zasilana losowymi zestawami danych, które nie są oznaczone i nie są uporządkowane. Maszyna musi wymyślić, jak uzyskać wyniki. Na przykład, jeśli zaoferujesz mu softball w różnych kolorach, powinien być w stanie kategoryzować według kolorów. Dzięki temu w przyszłości, gdy maszyna zostanie zaprezentowana z nową piłką do softballu, będzie mogła zidentyfikować piłkę z już istniejącymi etykietami w swojej bazie danych. W tej metodzie nie ma danych uczących. Maszyna musi się sama uczyć.
Nauka wzmacniania
Do tej kategorii należą maszyny, które mogą podejmować sekwencję decyzji. Następnie istnieje system nagród. Jeśli maszyna radzi sobie dobrze z tym, czego chce programista, otrzymuje nagrodę. Maszyna jest zaprogramowana w taki sposób, że łaknie maksymalnych nagród. Aby to osiągnąć, rozwiązuje problemy, opracowując różne algorytmy w różnych przypadkach. Oznacza to, że komputer AI wykorzystuje metody prób i błędów, aby uzyskać wyniki.
Na przykład, jeśli maszyna jest pojazdem autonomicznym, musi tworzyć własne scenariusze na drodze. Nie ma mowy, aby programista mógł zaprogramować każdy krok, ponieważ nie może wymyślić wszystkich możliwości, gdy maszyna jest w drodze. Tu właśnie wkracza uczenie przez wzmacnianie(Reinforcement Learning) . Można to również nazwać sztuczną inteligencją prób i błędów.
Czym różni się głębokie uczenie od uczenia maszynowego(Machine Learning)
Głębokie uczenie(Deep Learning) jest przeznaczone do bardziej skomplikowanych zadań. Głębokie uczenie(Deep Learning) jest podzbiorem uczenia maszynowego(Machine Learning) . Tyle tylko, że zawiera więcej sieci neuronowych, które pomagają maszynie w uczeniu się. Sieci(Manmade) neuronowe stworzone przez człowieka nie są nowe. Laboratoria(Labs) na całym świecie próbują budować i ulepszać sieci neuronowe, aby maszyny mogły podejmować świadome decyzje. Musiałeś słyszeć o Sophii(Sophia) , humanoidzie z Arabii Saudyjskiej(Saudi) , która otrzymała regularne obywatelstwo. Sieci neuronowe są jak ludzkie mózgi, ale nie tak wyrafinowane jak mózg.
Istnieje kilka dobrych sieci, które zapewniają głębokie uczenie się bez nadzoru. Można powiedzieć, że Deep Learning to bardziej sieci neuronowe, które imitują ludzki mózg. Mimo to, przy wystarczającej ilości przykładowych danych, algorytmy Deep Learning mogą być używane do pobierania szczegółów z przykładowych danych. Na przykład za pomocą procesora obrazu DL łatwiej jest tworzyć ludzkie twarze, w których emocje zmieniają się w zależności od pytań, jakie są zadawane maszynie.
Powyższe wyjaśnia AI vs MI vs DL w łatwiejszym języku. AI i ML to ogromne dziedziny – które dopiero się otwierają i mają ogromny potencjał. To jest powód, dla którego niektórzy ludzie są przeciwni używaniu uczenia maszynowego(Machine Learning) i głębokiego uczenia(Deep Learning) w sztucznej inteligencji(Artificial Intelligence) .

About the author
Jestem inżynierem Windows, ios, pdf, błędów, gadżetów z ponad 10-letnim doświadczeniem. Pracowałem nad wieloma wysokiej jakości aplikacjami i frameworkami Windows, takimi jak OneDrive dla Firm, Office 365 i nie tylko. Moja ostatnia praca obejmowała opracowanie czytnika PDF dla platformy Windows i pracę nad tym, aby komunikaty o błędach były bardziej zrozumiałe dla użytkowników. Dodatkowo od kilku lat jestem zaangażowany w rozwój platformy ios i dobrze znam zarówno jej funkcje, jak i dziwactwa.
Related posts
Organizator SMS: Aplikacja SMS oparta na uczeniu maszynowym
Fakty, mity, debata o sztucznej inteligencji
Co to jest głębokie uczenie i sieć neuronowa
Najlepsze darmowe oprogramowanie do sztucznej inteligencji dla systemu Windows 10
Jak zainstalować Drupala za pomocą WAMP w systemie Windows
Jak chronić i zabezpieczać dokumenty PDF hasłem za pomocą LibreOffice
Dziewięć Nostalgic Tech Sounds, których prawdopodobnie nie słyszałeś od lat
Wystąpił błąd podczas sprawdzania aktualizacji w VLC
Różnica między komputerami analogowymi, cyfrowymi i hybrydowymi
Co to są wirtualne karty kredytowe oraz jak i gdzie je zdobyć?
Zablokowany dostęp do Plex Server i ustawień serwera? Oto poprawka!
Jak używać szablonu do tworzenia dokumentu w LibreOffice
Jak przekonwertować plik binarny na tekst za pomocą tego konwertera tekstu na binarny?
Aplikacja do przesyłania wiadomości sesyjnych zapewnia silne zabezpieczenia; Numer telefonu nie jest wymagany!
Etykieta wideokonferencji, wskazówki i zasady, których należy przestrzegać
Co to jest analiza danych i do czego służy
Co oznacza NFT i jak stworzyć NFT Digital Art?
Najlepsze narzędzia do wysyłania SMS-ów za darmo z komputera
Konwertuj linki Magnet na linki bezpośredniego pobierania za pomocą Seedr
Fix Partner nie połączył się z błędem routera w TeamViewer w systemie Windows 10