Co to jest Web Scraping i jak działa w cyfrowym świecie
Dane(Data) i informacje to dwa terminy, które są często używane zamiennie, ale istnieje między nimi znacząca różnica. Na przykład dane odnoszą się do bitów informacji, ale nie do samej informacji. Z drugiej strony Informacje(Information) to zbiór danych, które są przetwarzane w sensowny sposób. Ze względu na przytłaczające dane dostępne w Internecie, różne metody, takie jak Web Scraping , Web Harvesting lub Web Data Extraction , są wykorzystywane do generowania praktycznych i zmieniających grę spostrzeżeń dotyczących korzystania z Internetu(Internet) . Ale co dokładnie oznaczają w świecie online. Spójrzmy!
Jak działa drapanie stron internetowych?
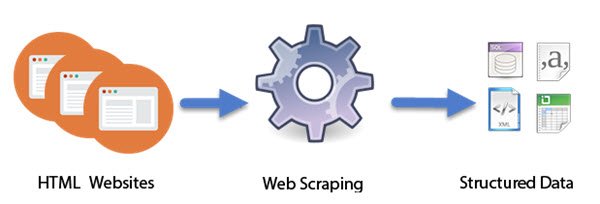
Programy komputerowe(Computer) zaprojektowane jako inteligentne(Intelligent) boty wykonują pracę Web Scraping . W przeciwieństwie do screen scrapingu, który kopiuje tylko piksele wyświetlane na ekranie, web scraping wyodrębnia podstawowy kod HTML , a wraz z nim dane przechowywane w bazie danych. Podejście stało się dość popularne. W rzeczywistości jest uważany za jedną z podstawowych umiejętności do zdobycia w dzisiejszym cyfrowym świecie. Ma kilka świetnych zastosowań w kompilacji dużych zbiorów danych, fundamentalnych dla technik takich jak:
- Analiza Big Data(Big Data Analytics)
- Nauczanie maszynowe
- Sztuczna inteligencja(Artificial Intelligence)
Wraz z szybkim rozwojem informacji cyfrowych dostęp do Big Data za pomocą metody Web Scraping lub Web Data Extraction stał się znacznie łatwiejszy. To powiedziawszy, Web Scraping może być używany w firmach cyfrowych, które polegają na zbieraniu danych zarówno w przypadkach uzasadnionych(Legitimate) , jak i nielegalnych. Pierwsza obejmuje przykłady Benevolent Web Scraping(Benevolent Web Scraping Examples) , podczas gdy druga zawiera przykłady złośliwego scrapowania sieci Web(Malicious Web Scraping) .
Przykłady Benevolent Web Scraping
- Boty wyszukiwarek(Search) indeksujące witrynę, analizujące jej zawartość w celu przypisania rangi na podstawie określonych wyników, np . Google .
- Witryny porównujące ceny(Price) wdrażające boty do automatycznego pobierania cen produktów
- Firmy badające rynek(Market) wykorzystujące skrobaki do wydobywania danych z mediów społecznościowych (np. do analizy nastrojów, osobistych preferencji itp.).
Przykłady złośliwego drapania w sieci
Web Scraping do celów niezgodnych z prawem może spowodować poważne straty finansowe, jeśli dane zostaną pobrane bez zgody właścicieli witryn. Dwoma najczęstszymi przypadkami użycia złośliwego drapania w sieci(Malicious Web Scraping) są wyłuskiwanie cen i kradzież treści.
- Obniżanie cen(Price Scraping) — boty Scraper sprawdzają konkurencyjne biznesowe bazy danych, aby uzyskać dostęp do informacji o cenach, podcinać konkurencję i zwiększać sprzedaż.
- Kradzież treści(Content Theft) — ta nielegalna działalność obejmuje kradzież treści na dużą skalę z docelowej witryny internetowej. Typowe cele obejmują głównie katalogi produktów online i witryny internetowe, które wykorzystują treści cyfrowe do napędzania biznesu.
Mam nadzieję że to pomoże!

About the author
Jestem profesjonalnym technikiem komputerowym i posiadam ponad 10-letnie doświadczenie w branży. Specjalizuję się w tworzeniu Windows 7 i Windows Apps, a także w projektowaniu Fajnych Stron Internetowych. Mam ogromną wiedzę i doświadczenie w tej dziedzinie i byłbym cennym zasobem dla każdej organizacji, która chce rozwijać swoją działalność.
Related posts
Brak połączenia z Internetem, ale wyświetla się jako Połączony z Internetem
Czym jest Bitcoin, cyfrowa waluta
Co dzieje się z Twoimi kontami online, gdy umrzesz: Zarządzanie zasobami cyfrowymi
Co to jest ciemna sieć lub głęboka sieć? Jak uzyskać dostęp i środki ostrożności.
Korzyści z przyjmowania Digital Detox i jak się do tego zabrać
Surferzy vs właściciele stron internetowych vs blokery reklam vs wojna przeciwko blokerom reklam
Rozproszone ataki typu „odmowa usługi” DDoS: ochrona, zapobieganie
Jak skonfigurować połączenie internetowe w systemie Windows 11/10?
Co oznaczają typowe błędy kodu stanu HTTP?
Sprawdź, czy Twoje połączenie internetowe jest w stanie przesyłać strumieniowo treści 4K
Nie możesz połączyć się z Internetem? Wypróbuj kompletne narzędzie do naprawy internetowej
Internet nie działa po aktualizacji w systemie Windows 11/10
Napraw błąd odzyskiwania strony internetowej w przeglądarce Internet Explorer
Ataki Brute Force — definicja i zapobieganie
Jak oszczędzać energię baterii podczas przeglądania sieci w przeglądarce Internet Explorer?
Ikona sieci mówi Brak dostępu do internetu, ale mam połączenie
Wyjaśnienie frontingu domeny wraz z niebezpieczeństwami i
Jak dodać zaufaną witrynę w systemie Windows 11/10?
Aplikacje Edge i Store nie łączą się z Internetem — błąd 80072EFD
Co to są domeny zaparkowane i domeny wpuszczane?